
TDD: Three easy mistakes
TL;DR Small increments of value

Back in 2014 I wrote a blog post listing three mistakes often made by folks who are new to test-driven development (TDD). It was a very long post, so I’ve taken the three parts and expanded each into its own article, also incorporating the comments I received in 2014. This is part 1.
Each time I visit a team that is relatively new to TDD I find the same basic mistakes cropping up every time. The three mistakes I see most often are:
Starting with error cases or null cases.
Writing tests for invented requirements.
Writing a dozen or more lines of code to get to GREEN.
This article will deal with the first of these...
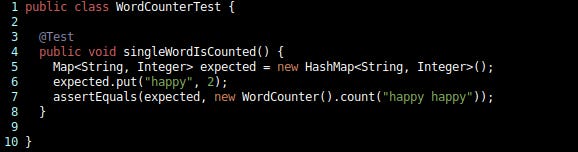
Imagine you have to test-drive the design of an object that can count the number of occurrences of each word in a string. I will often see someone who is new to TDD start with tests such as these (example in Java/JUnit):

Tests like this are counter-productive for a number of reasons:
They feel easy to write, and give a definite feeling of progress. But that is all they give: a feeling of progress. These tests really only prove to ourselves that we can write a test. When written first like this, they don't deliver any business value.
These tests don’t get us closer to validating the Customer1's assumptions. Time spent writing them hasn’t allowed us to demo anything or ask for feedback. There is no business benefit and no learning benefit.
These edge-case tests increase the code’s cost of ownership; by putting this code into the codebase too early I find it just gets in the way. Chances are we’ll have to tiptoe around them while we build the actual business value, and that will slow us down even more.
It is usually much better to begin by building a simple thin slice of positive business value (some folks call this a “happy path”, to remind themselves that no error cases have been dealt with yet). And when we’re successfully delivering some business value, that is the time for us to remind our Customer that we have some edge cases to consider.
So start with tests that represent business value and allow a thin, usable slice of the product to be built quickly. For example:
This way you will get two major benefits:
Firstly, you can ask the Customer that vital question (“Is this what you meant?”) sooner, and they will invest less before they know whether they want to proceed. So the biggest payoff of leaving the edge cases until later is that they actually allow the Customer, should they decide to do so, to ship working code that provides benefit. Sure it may have limited robustness, but that risk can be worth more than waiting until you have finished polishing every edge case that can be thought of.
")
And secondly, you will likely have a simpler development job to do, both while developing the happy path and later when you come to add the edge cases. Because very often it will turn out to be much easier to add edge cases to an existing solution, after the happy path is done. In fact some of the edge cases may now already be dealt with "for free", as it were, simply by the natural shape of the algorithm we test drove. Others may be easy to implement by adding a Decorator or introducing a guard clause.
Now, you might object to me calling this a mistake, because tests such as those above allow us to define a class API without having to worry about the implementation. There are a number of design decisions that have been made as a result of writing some very quick tests, e.g. the name of the class (WordCounter), the name of the method that does the counting (count), whether the parameters are on the count method or the class constructor, etc. But I don’t see those as a benefit; to my mind they create risk because they haven't been checked in realistic scenarios. I would prefer to make those design decisions in code that is delivering business benefit so that, ultimately, they are required to support real users. In short, I want a correct algorithm first, followed by habitable code.
Things to try
Next time you have to write the first test for something new, try to deliver positive business value from the happy path.
Review your existing edge-case and error-case logic: how much of it could be pushed out of your domain code and into decorators or CHECKS?
Next time, another TDD rookie mistake…
I’ve decided to switch from Product Owner to the XP term Customer henceforward, because that’s the term I’m more comfortable with.
This story reminds me of the many times when I found that the only tests that exist for a class were the ones about invalid input, but none for the actual computation/algorithm then. Looking forward to the next article!