
Javascript Checkout - Triangulation 2
In which I agonise over how much duplication to remove

This article is part 5 in a series in which I’m doing a well-known code kata in the “TDD as if you meant it” style. I’m also strictly following the 4 rules of simple design and looking for opportunities to use implicit coupling to drive refactoring under the Once And Only Once rule. (If you missed the start of this series you can catch up with part 1 here.)
Last time I decided to compare two different approaches to test-driving this kata. We’re currently working on a branch while we explore triangulation, and then we’ll go back to main to explore the alternative approach of fixing the coupling first.
Currently on the branch we have this code:

I’m satisfied that this tells the Customer’s story well enough for now, so it’s time to move on to rule 3 and look at coupling issues. A quick glance shows me the following:
The price of an A is 50, which is known by lines 4, 14, and 15.
The price of a B is 30, which is known by lines 6 and 15.
Lines 3-6 are coupled to the lengths of the test arrays somehow.
There may be more, but I don’t feel it matters if we don’t see it all now. After we’ve done some cleaning up we’ll regularly look at the code again and again, and I think we’ll be more likely to spot other coupling (if it’s there) when we have somewhat cleaner code.
So, which to fix first. Again I’m not sure it matters, so I’m going after that 50, simply because it’s the most obvious.

The value 50 is arbitrary, but something somewhere must know it; so we can’t remove it altogether and it needs to be defined somewhere. So I can see five options:
Define the price of A in the code and let the test access it.
Define the price of A in the test and let the code access it.
Define the price of A in the code and pass it to the test.
Define the price of A in the test and pass it to the code.
Define the price of A somewhere else and access it from both the code and the test.
Options 2 & 3 would create a dependency from the code to the test, so we rule them out right away. Option 1 violates the intent of the kata (the pricing rules should be easily changeable without changing code). And for option 5 I don’t yet have anywhere else available. So option 4 feels the lightest touch for now.
I add a parameter:

The tests pass, so I commit: uncouple the code from the price of A. And to stick with my intended discipline, I now return to the 4 Rules again.
Does this code express my intention? Actually, for now I think it does, so I move on to rule 3 again. The code is now explicitly coupled to the price of A, which is a clear improvement; but it is still implicitly coupled to that 30 for the price of B. And what do you make of the several places in the test that mention 50? What would you do about that? Take a moment to consider the options before reading on — and please leave a comment explaining your reasoning if you have the time.
My preference is to leave the test as it is — at least for now — for a couple of reasons. Firstly, all of the 50 instances are now in one function; so although lines 14, 15, and 17 are implicitly coupled together, they are all within a single encapsulation unit and so the risk of something breaking is low and the cost of fixing it is also low. We should make a mental note to review this decision if the test gets much bigger, or if it gets broken up into helper functions or suchlike. But for now, the potential problem is contained and localised, so I’m not concerned about it.
Secondly, I feel there’s more mileage in addressing the coupled 30 instances first. Because when I’ve done that I may begin to see patterns of similarity that link the 50s and the 30s, so my next round of refactoring could have more information to build on. That is, if I fix similar problems twice in a row (the 50s, then the 30s) I’m hoping I may have more self-similarity to shoot for afterwards; whereas if I press on with the 50s I may not see some nice symmetries until I’ve expended a lot of effort. In general I have a preference for breadth-first tree walks — fix the 50s a little, fix the 30s a little, fix the 50s a little more, fix the 30s a little more, see the patterns that emerge, …
But there are trade-offs here, as always. Let’s imagine for a second that I “fix” the duplication by defining the price of A in exactly one place:

Line 17 gives me cause for concern, because now it explicitly duplicates the algorithm from the code. Look ahead at the remaining tests in the kata and you’l see that later test cases will become more and more complicated and I’ll have dozens of lines of test code that effectively duplicate the code’s algorithm. So I have to make a trade-off: do I explicitly document how the test values were derived, or do I explicitly document the expected outcomes, and expect the reader to do the calculations in their head? The second variant above would have the advantage of allowing me to replace the static 50 with an arbitrary — maybe even randomly generated — value. I feel that would give me better coverage, and would be a step on the road to property-based testing this code. So maybe as the forces within this code change I’ll reconsider, but right now I like the clarity of having the explicit 50 in the test expectation.
Reverting back to the committed code, I make a similar change and inject the 30 as a parameter:
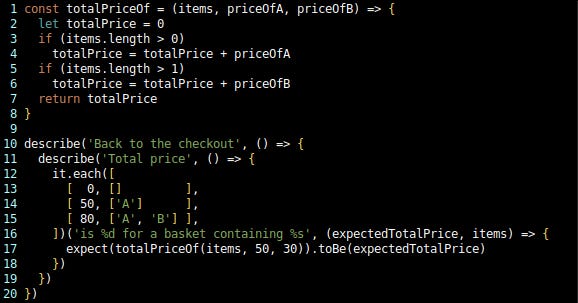
Commit: uncouple the code from the price of B.
As per usual, it’s now time to sit back and reflect on how well this code tells its story, and whether I’ve introduced any (more) implicit coupling. For example, we can now clearly see additional symmetries caused by the introduction of priceOfB. Do they help us or hinder us in understanding the code? What would you change next?
Things to try
Next time you have a choice between depth-first and breadth-first tree walking, try breadth-first and look out for symmetries appearing sooner.
Explore property-based testing: is it appropriate for the code you’re currently writing?
As always, if you try these please let me and your fellow readers know.
I probably should have raised this last time, but why did you key off length (lines 3 and 5) rather than contents? Are you intentionally avoiding domain knowledge?