
Javascript Checkout 3
In which my tests become explicitly coupled and names change many times

This article is part 3 in a series in which I’m doing a well-known code kata in the “TDD as if you meant it” style. I’m also strictly following the 4 rules of simple design and looking for opportunities to use implicit coupling to drive refactoring under the Once And Only Once rule. (If you missed the start of this series you can catch up with part 1 here.)
In part 2 I increased the amount of duplication, so that my tests both told the same story consistently. So currently I have this code:
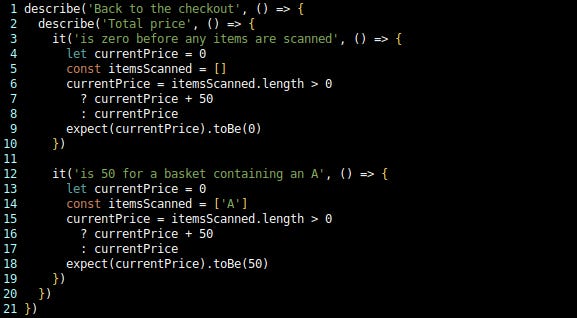
Let’s review this from the point of view of the 4 Rules: Firstly, these tests are passing. And there is no other code, so by definition everything must be covered by tests (another benefit of TDD As If You Meant It). Second, do these tests clearly tell the story my Customer told me? Honestly, I can’t really tell; they look as if they probably do, but code this verbose is quite hard to review for readability. The noise from that duplication is so loud that I can’t get past it — and so I think I have to fix it before I can do any more.
Speaking of noisy duplication…

The only difference between the two tests is that ‘A’ in the itemsScanned array. That difference should be standing out loud and proud, informing the reader that it is the entire reason for the existence of the second test. But it is currently buried in the mass of code, and so the tests look too similar to be useful. But that ‘A’ is the clue that tells me I need to Extract Method and give it a parameter. I’ll extract into this test file for now, because until I’ve done that I won’t really know what to call it. So:

Commit: Extract checkout function. (I named it checkout for now, because that’s the name of the kata we’re doing.)
The good news here is that these tests are now explicitly coupled: they are clearly testing the same thing, and if it changes they will both test the changed thing. What was previously implicit — our intention that these tests should be coupled — is now explicit, and we can read that in the code locally.
So now it’s back around the 4 Rules. Well, the tests are still passing, so that’s good. But in extracting this function I’ve added a new name (checkout) to our domain model and I’ve changed the nature of itemsScanned from being a constant to being a function parameter. This is the “dynamo” that Joe Rainsberger talks about: every time we fix a Once And Only Once violation we change the set of names we’re using. So rules 2 and 3 go round and round.
All of which means that I must now review the names I’m using and the story they are telling. It would be tempting to start at the top of the source code and read down, looking at the names in turn. But the names are only “good” or “bad” in context; I need to start with the story and adjust the names until they work as a narrative. So I begin at the “outside”, with the tests.
The first thing I notice is that lines 10, 12, and 13 are intended to refer to the same domain concept, but use two different names for it. I think this is another subtle case of implicit coupling: I want the reader to make a connection between the description of the test and its implementation, but that link is currently only implied at best. The description “total price” feels more correct (subjective application of domain knowledge?), so I rename the variable in both tests to match:
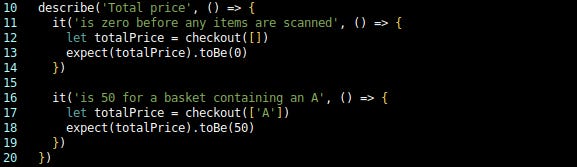
Commit: Rename variable to match the domain.
I read these tests again and now I’m not sure that checkout is right. Would scan be a better fit? It’s cheap to find out:

Yes, that feels better: I scan a list of items and get back a total price. Commit: Rename function to tell a clearer story.
Now I notice that totalPrice could be a const. And in fact, as it doesn’t change and is used only once it could be inlined. Do I want to lose the expressive power of having the extra name here? Only one way to find out:

Hmmm. Each test now has three closing brackets together, which definitely makes me slow down when attempting to parse the code. But I have a general distrust of temporary variables (even though this one is a const), so right now I feel quite conflicted. This code now feels more “technical” and thus harder to read; but it has one fewer variable, and that’s something I usually strive for.
If I were to keep this version I feel the name scan now doesn’t help as much as totalPrice used to; I’m inclined to press on without the const, but with the previous vocabulary. How about this:

That definitely reads better (tells the story to my Customer), but those nested brackets are still irksome. Actually, the innermost pair of brackets could be removed from those expressions (lines 12 and 16) if the list of items had a name. But that would introduce another temporary variable, which is something I’m trying to avoid. Unless I look at the two tests together and realise that they are incredibly similar. Could I replace them with a single parameterized test? A quick Google tells me I can do this:

And when this runs, the output looks like this:

I definitely like the test output, and I think line 15 reads better than either test did in the previous version. I still have to pause when reading those arrays on lines 12-13 though, so I wonder whether I can use whitespace to help:

Yes, I think I can tolerate that. It’s really line 15 that is the big attraction of this approach, I suspect because I have extra names (the test parameters) without having extra temporary variables. Commit: Replace the tests with a table of cases.
So now I’m happy that the tests tell their story fairly well, let’s drill down one level of abstraction and look at the function we’re testing:

Two problems strike me here: First, the domain concept of “scanning” isn’t mentioned anywhere else now; and second, there’s a wee bit of friction between the names currentPrice and totalPriceOf. I’m cavalier enough to think that I can fix both of these in one edit:

For once my cockiness pays off. Commit: Change local names to match the domain. And now that my attention isn’t diverted by those names, I see that line 5 looks like overkill. Do I really need a ternary just to add 50 to 0?

That’s better, and I think it tells the story more clearly too. Commit: Clarify the totalling algorithm.
That feels like a lot for today, so it’s time to quickly recap. I began by fixing a violation of the Once And Only Once rule; but I think it’s more important to say that I explicitly coupled the tests to each other, as intended by both the Developer (me) and the Customer (also me).
I then spent quite a few moves on telling the story; and once or twice I found that simplifying the story and/or the names also allowed me to see other duplication or superfluous elements that I had previously missed. Reader Walter Nuccio commented on Runtime and compile time suggesting that we could view the second Rule (expresses intent) in terms of explicit coupling too: The names we use should be explicitly coupled to domain concepts, and the story told by the Customer should be explicitly represented in the code. This is what I’ve tried to do with these naming moves today.
Right now I’m pretty happy with this code, so next time I plan to move along and add the next test. But I will nevertheless begin with a read through the code to check how well it communicates; because currently my perception is heavily influenced by the fact that I just spent a couple of hours right here in this context, and so I’m biased by today’s momentum.
Does all of this feel too slow to you? I think it only seems slow because I’m calling out my thinking as we go along. Try it yourself and let us know how it feels.
Things to try
When you’re assessing whether your code tells its story, start at the outside and work inwards only when the outer layers of abstraction communicate extremely well.
Next time you have to refactor, consciously cycle around the 4 Rules. In particular each time you change anything, start again with a new review of the names and the story they tell.
As always, please share your results by leaving a comment if you try these.
I also received this comment via email from Bill Wake (reproduced here with permission):
"Hi -
I'm enjoying your series.
I liked the move to parameterized tests, but felt like the arguments & message would read better in the other order. Sort of the difference between "Press 4 for the pharmacy department" vs. "For the pharmacy department, press 4" - a little less state to maintain.
I don't know if that's just a personal philosophy or if it resonates:)
Take care,
BIll"
I like your focus on getting the names right. It's something that is usually overlooked, in particular between the tests labels and the code itself.
I would personally have kept the `const` in the tests instead of reaching out for parametrized tests. That's probably because I tolerate short-lived, non-reassignable, temp variables. I also like to see that kind of "Arrange-Act-Assert" structure. I feel the parametrized tests is more technical and harder to read from the source code—although the report is clear enough and it does DRY the code.
Now, at this point, either ways work. It's too early to tell which direction I would prefer in the end. So I like that you are taking these steps I wouldn't take for me… and I'm curious to see where we will land 😃